Hello all, we have gotten some reviews back. Curiously the reviewers asked us to say why the 90s ct work with security failed. I was not aware of such work, the reviewer didn't provide any examples. The only person I can think of is @dusko and we have already cited recent work in cryptography and CT. Anyways, anybody that knows anything about this please let me know.
I'll take work on coalgebras and security modeling as well if anybody knows of it. Microsoft academic and google scholar is pulling a blank
@Mike Stay
Sorry, I only got into CT around 2007; I've never heard anything about CT in security beyond static analysis and formal crypto.
Could you send some examples of this work?
@Mike Stay forgot to ping my bad
Here's a random selection of stuff.
https://math.berkeley.edu/~izaak/assets/cryptocat.pdf
https://research.fb.com/wp-content/uploads/2016/11/from_categorical_logic_to_facebook_engineering.pdf
https://www.youtube.com/watch?v=Njw5Aad-gBQ
https://www.sciencedirect.com/science/article/pii/S089054019…-S0890540198927407-main.pdf&usg=AOvVaw3Q0jqZDh3ph5tHI6Piie4N
https://www.sciencedirect.com/science/article/pii/S1567832604000049
http://web.stanford.edu/class/cs259/WWW04/lectures/13-Security%20in%20Process%20Calculi.pdf
https://link.springer.com/chapter/10.1007/978-3-642-54789-8_19
https://arxiv.org/abs/1301.3393
https://dl.acm.org/doi/10.1145/2641483.2641529
Thanks a bunch!
sorry that i didn't notice this question. you should have asked me directly.
to me, asking whether there is work applying CT to security is like asking whether there are novels in german about fashion. the problem with that question is that any novel about fashion can be translated to german, and that any novel in german about fashion can be translated to other languages. grothendieck nearly proved the weil conjecture in CT a couple of itmes, but passed by it, since there was more to it than that. then deligne spelled it out, and then others translated it out of CT. on the other hand, almost every result in almost anything can be translated into CT. the question is whether it helps, and whether it becomes easier to sing in the new langauge.
i wrote a bunch of papers on security, and if you read them and know categories, you will find categories are always there, whether i mention them or not. but i think in categories, and they are in all my papers. but i worked in various communities, including security protocols, and in many of them if you want to empty the room, you say "categories" and everyone leaves. so you adapt the language. that social effect is at least to some extent a consequence that the category theory community at some point in the 70s started sounding like a political party. eilenberg hated that, but others had such instincts. so people started thinking of it as some sort of ideology. and such misunderstandings have a self-realizing power...
all of my protocol analysis work was based on a process model, the cord calculus. all such process models are monoial categories: see eg "Categorical logic of names and abstraction" from late 90s. i think in MSCS. so every protocol analysis that you see in any of the papers (eg we broke the GDOI option of IPSec like 6 months after it got standardized) was worked out in a monoidal category. the tool that we built and delivered (was still in use in 2013) --- was an implementation of monoidal categories with an s-expression API. i think we announced the GDOI fix in ESORICS, could be 2004?...
explicitly categorical model was i think
https://arxiv.org/abs/1203.6324
not sure whether we use explicit functors in
https://arxiv.org/abs/1106.0706
but that setup is fairly obviously a pair of fibrations Logic (views) ---> Processes ---> Network.
this
https://arxiv.org/abs/0802.1306
was also implemented: using i think twisted comma construction to detect link farming.
that model was reused over and over in various tools:
https://arxiv.org/abs/1011.5696
funny enough, expanding the spectral decomposition applications led to the "pure" result which i cherish more than the rest of it together:
https://arxiv.org/abs/2004.07353
but SORRY for pushing my work. people become talkative as they age :)
This answer should be required reading for everyone who asks about applied category theory-in-the-recent-sense
Great answer, @dusko. On a completely irrelevant note, I don't think this is accurate:
grothendieck nearly proved the weil conjecture in CT a couple of times, but passed by it, since there was more to it than that. then deligne spelled it out, and then others translated it out of CT.
There are a number of Weil conjectures, Grothendieck developed a lot of mathematics to prove them and succeeded in proving all but the final, most interesting one - an analogue of the Riemann Hypothesis for function fields of algebraic varieties. He succeeded in reducing this to some conjectures now called the standard conjectures, but these remain unproved to this day! Then Deligne came in and used Grothendieck's ideas together with a bunch of very different ideas of his own to finish the job.
John Baez said:
Great answer, dusko. On a completely irrelevant note, I don't think this is accurate:
grothendieck nearly proved the weil conjecture in CT a couple of times, but passed by it, since there was more to it than that. then deligne spelled it out, and then others translated it out of CT.
There are a number of Weil conjectures, Grothendieck developed a lot of mathematics to prove them and succeeded in proving all but the final, most interesting one - an analogue of the Riemann Hypothesis for function fields of algebraic varieties. He succeeded in reducing this to some conjectures now called the standard conjectures, but these remain unproved to this day! Then Deligne came in and used Grothendieck's ideas together with a bunch of very different ideas of his own to finish the job.
i said "nearly proved" didni :)) can any statement about history be accurate? as the word says: it's all hi stories. but you are right, we should at least try to make sure that the hi-cells are groupoids :)
There is this paper, Universally composable security: A new paradigm for cryptographic protocols, that is widely cited (>3k) for cryptographic protocols -- the original is from 2000 but its been continuously evolving.
what do you guys thing of this? and what are its parallels to CT?
https://eprint.iacr.org/2000/067.pdf
Hi,
I have described what I think a very efficient security protocol for the web, which I called HttpSig which is both pretty simple and is needed to build a decentralised social web. (some initial discussion). This may be too simple to be able to do formal analysis on, but perhaps not? (I assume cryptographers have done their job, so I am not sure if this falls under cryptographic protocols, as used in the above paper).
(The complexity arises at the next stage when describing the reasoning of how User-Agents can determine if they should be granted access given some credentials they have and the rules published by the resource, and how Guards can determine if the User Agent is allowed access given a submitted proof. We would like to be able to use DL reasoning there, as that is well studied. )
Security related: The W3C Verifiable Credentials Group is looking for reviews of the document attached to this email RDF Dataset Canonicalization - Formal Proof.
There will very likely be a W3C Working Group on the subject soon. So further mathematical insight would be very valuable. There is a history of papers (many from HP) going back at least to 2004 on this subject. See the mailing list thread for further references.
The W3C is starting work on a charter for Linked Data Signatures as per mail to the Credentials Community Group today. There'll be graphs, hypergraphs, URIs and crypto discussions involved, and mathematical proofs of correctness will play a major role - even if they have to be balanced with a lot of practical considerations.
Kevin Buzzard wrote on the Lean zulip
My reading of the Formal Proof document is that this is someone using the phrase "formal proof" the way that a mathematician would use the phrase "proof" and a computer formaliser person would use the phrase "paper proof".
To which I replied
Thanks Kevin , I thought that may be the case.
But in their defense, this is not a standard, only a proposal for one, and I guess they are still interested in getting feedback from the community, discovering if others have come up with better methods, etc... You can actually see quite a lively discussion on the mailing list on the RDF Dataset Canonicalization thread.
Btw. DataSets in RDF I believe form hypergraphs, as defined say in David Spivak's Higher-dimensional models of Networks. I think those are generalisations of simplicial sets. From that you can build multi agent modal logics as shown by this beautifuly illustrated Knowledge in Simplicial Complexes (I have an illustrated document that shows how one can get to such a conclusion with simple illustrations :-).
Also a number of links to this here.
I mention that because it is usually thought that RDF Graphs are only directed graphs. That these higher dimensions are needed for the web, which is a multi-agent system spanning the globe, is often lost on people, even logicians, mathematicians and programmers. (But that is fine, since those graphs are part of the larger space).
Also I mention that because someone might thinking of this see some powerful mathematical tool that can be used in this space, and that may have escaped those who thought about it till now. Also of course this may be an interesting and valuable exercise to try to see if one can prove this mechanically. As there are a lot of computer people in those groups, I think they would appreciate such proofs a lot.
Three years ago I came across @dusko's 2012 Paper "Tracing the Man in the Middle in Monoidal Categories" which has this really great paragraph:
We propose to apply categorical methods of semantics of interaction to security. The MM attack pattern, formalized in cord calculus, originally designed for protocol analysis, naturally leads to a categorical trace structure, generalizing the traces of linear operators in this case by means of a coalgebraic, iterative structure of the term algebra used in computation and communication. In the MM-attacks on authentication protocols, the intruder inserts himself1 between the honest parties, and impersonates them to each other. MM is the strategy used by the chess amateur who plays against two grand masters in parallel, and either wins against one of them, or ties with both. MM is also used by the spammers, whose automated agents solve the automated Turing test by passing it to the human visitors of a free porn site, set up for that purpose [20]. MM is, in a sense, one of the dominant business model on the web, where the portals, search engines and social networks on one hand insert themselves between the producers and the consumers of information, and retrieve freely gathered information for free, but on the other hand use their position in the middle to insert themselves between the producers and the consumers of goods, and supply advertising for a fee. In security protocols, MM is, of course, an interesting attack pattern. The fact that an MM attack on the famous Needham-Schroeder Public Key (NSPK) protocol [40] remained unnoticed for 17 years promoted this toy protocol into what seemed to be one of the most popular subjects in formal approaches to security. Although the habit of mentioning NSPK in every paper formalizing security has subsided, we remain faithful to the tradition, and illustrate our MM-modeling formalism on the NSPK protocol. More seriously, though, the hope is that this formalism can be used to explore the scope and the power of the MM pattern in general, and in particular to formalize the idea of the chosen protocol attack, put forward a while ago [30], but never explored mathematically.
The whole point of the work we have been doing on Solid is to create the technology to remove the need for the Man in the Middle architecture and business model so well described in that paragraph, by making it possible to develop decentralised apps where every individual can store the information on their own server and link to access controlled information on another.
Somehow I have not been able to read up more about the literature and mathematics that this paper put forward. Has this been superseded now? Or is there a good introduction that would allow me to get to grip with it quickly? We did not have Zulip at the time so I would not have known who to ask.
zkao said:
There is this paper, Universally composable security: A new paradigm for cryptographic protocols, that is widely cited (>3k) for cryptographic protocols -- the original is from 2000 but its been continuously evolving.
what do you guys thing of this? and what are its parallels to CT?
https://eprint.iacr.org/2000/067.pdf
this was ran canetti's thesis. he spelled out the idea more succinctly in FOCS 2001. if anyone told him at the time that using the word composition might awake categorical associations, he would probably make an honest effort to try to find another word :)
Henry Story said:
Three years ago I came across dusko's 2012 Paper "Tracing the Man in the Middle in Monoidal Categories" which has this really great paragraph:
We propose to apply categorical methods of semantics of interaction to security. The MM attack pattern, formalized in cord calculus, originally designed for protocol analysis, naturally leads to a categorical trace structure, generalizing the traces of linear operators in this case by means of a coalgebraic, iterative structure of the term algebra used in computation and communication. In the MM-attacks on authentication protocols, the intruder inserts himself1 between the honest parties, and impersonates them to each other. MM is the strategy used by the chess amateur who plays against two grand masters in parallel, and either wins against one of them, or ties with both. MM is also used by the spammers, whose automated agents solve the automated Turing test by passing it to the human visitors of a free porn site, set up for that purpose [20]. MM is, in a sense, one of the dominant business model on the web, where the portals, search engines and social networks on one hand insert themselves between the producers and the consumers of information, and retrieve freely gathered information for free, but on the other hand use their position in the middle to insert themselves between the producers and the consumers of goods, and supply advertising for a fee. In security protocols, MM is, of course, an interesting attack pattern. The fact that an MM attack on the famous Needham-Schroeder Public Key (NSPK) protocol [40] remained unnoticed for 17 years promoted this toy protocol into what seemed to be one of the most popular subjects in formal approaches to security. Although the habit of mentioning NSPK in every paper formalizing security has subsided, we remain faithful to the tradition, and illustrate our MM-modeling formalism on the NSPK protocol. More seriously, though, the hope is that this formalism can be used to explore the scope and the power of the MM pattern in general, and in particular to formalize the idea of the chosen protocol attack, put forward a while ago [30], but never explored mathematically.
The whole point of the work we have been doing on Solid is to create the technology to remove the need for the Man in the Middle architecture and business model so well described in that paragraph, by making it possible to develop decentralised apps where every individual can store the information on their own server and link to access controlled information on another.
Somehow I have not been able to read up more about the literature and mathematics that this paper put forward. Has this been superseded now? Or is there a good introduction that would allow me to get to grip with it quickly? We did not have Zulip at the time so I would not have known who to ask.
i don't know whether traced monoidal categories as a model for MitM have been superseded, or have they not been pursued because the intersection of the community speaking the language and the community interested in the story was on the thin side. a bit like proposing latin as a good language for studying islamic theology. but i do know that the MitM has not been used because of shortcomings of architectures, but because it is useful to Man Zuck to insert himself in the Middle between friends, or to Man Gogol to insert himself between the advertizers and the world on one hand, and between the world and itself on the other... there are more up to date models of MitM in https://arxiv.org/abs/1904.05540 .
the readers of the MitM-by-traces paper will discern that the traced monoidal category is in this case a refinement of the kleisli category of convex algebras.
the main technical question of that paper is refining the majorization preorder and/or shannon entropy to eliminate exchangeability of the source, and to capture the actual information fusion practice (of every detective and cryptanalyst), where the source is processed in order of frequency. that problem is still WIDE OPEN, and not a $1B-problem byt a $100B-problem. can CT merge entropy and gradient descent? can CT make information bottlenecks tractable?
dusko said:
there are more up to date models of MitM in https://arxiv.org/abs/1904.05540 .
the readers of the MitM-by-traces paper will discern that the traced monoidal category is in this case a refinement of the kleisli category of convex algebras.
I really like this sentence in that paper
The web is a typical (re)source showing why privacy is so hard: it combines politics and thermodynamics.
Actually geo-politics and thermodynamics. At least that is my argument in the Web of Nations proposal.
Anyway, I think we can count @dusko as a Web Catster :-)
I do have a practical question right now regarding security. The Solid Authorization group is discussing what types of modes are needed to access a resource. (If you want to see how the sausage of standardisation processes goes you can quickly glance over here where you will find a lot of heat being expended on making some simple distinctions).
I referred to work on Lenses to argue that Read and Write modes are fundamental. But for discussions on sub/modes like Delete the consensus has been that the client needs write access to the deleted resource and to the container, because both are affected. Here it would be helpful to have a way to model the interaction between client and server as one between two actors in a principled way. Is there a structure where this would fall out nicely?
I would think that Delete could be implemented as a Write one level up the tree.
Is access downward closed, in the sense that read/write access to a parent node would also allow access to the children?
@Spencer Breiner it is an interesting question as to whether access should be downward closed. It would make sense that if you can Write a container, in the sense of delete it, that all internal resources depend on that. At the limit, if you own the Freedom Box (a.k.a. FB, as per Eben Moglen's talk in 2011) then you control all the containers in it as you can switch the box off.
But for the moment you may certainly want to allow some resources deeply nested inside protected containers (which to me seem very similar to the nesting of polys' in Spivak's recent work) to be public.
Spencer Breiner said:
I would think that Delete could be implemented as a Write one level up the tree.
yes. I have been writing a playground server using lenses here. I'll go and add DELETE to see how that looks...
Henry Story said:
I do have a practical question right now regarding security. The Solid Authorization group is discussing what types of modes are needed to access a resource. (If you want to see how the sausage of standardisation processes goes you can quickly glance over here where you will find a lot of heat being expended on making some simple distinctions).
I referred to work on Lenses to argue that Read and Write modes are fundamental. But for discussions on sub/modes like Delete the consensus has been that the client needs write access to the deleted resource and to the container, because both are affected. Here it would be helpful to have a way to model the interaction between client and server as one between two actors in a principled way. Is there a structure where this would fall out nicely?
the problem definition at
https://solid.github.io/authorization-panel/authorization-ucr/
is so general, that without an existing solution of this problem, very few organizations could function. e.g., if alice is not a student who drafted a resume, but a colonel who drafted a plan of a military campaign, and needs to discuss it with general Bob, then every military since ancient egypt had to have a solution for this problem. most recently in the 80s, when the US military needed to propagate its existing solutions to the world with computers, there was the Bell-LaPadula model, which predated lenses by reducing the narrative to Read and Write, and two simple rules: no Read-Up, and no Write-Down. but it's not just the military. the banks and the royalties, or whoever defended wealth, needed the same protocols, and in the 80s there was the Williams model. it is all in textbooks under AC and MLS. i may be thick, but i honestly don't understand what is new about this problem.
Ah the UCR, is just a use case document, to help open up some options as to where we could go. It has not gone through a lot of serious review yet.
What is new about Solid (Social Linked Data) is that it uses RDF (a first order logic for the web) to build the access control rules. So you could give read access to friends of your friends, or to people over 21, or to all people who went to a conference, and one should use decentralised identifiers and or verifiable credentials to allow people to prove their attributes.
Every resource has an associated access control rule that the client can read to establish which credentials to present, and the server can use to verify if an request can be authorised. illustration of Web Access Control I wrote up 7 years ago
The idea is to allow everyone to host their data on their Read/Write web server running on a Freedom Box, and have hyper-apps be able to follow linked data from one server to another, read WAC rules and present the right credentials.
That simplifies a lot, but that should help give the idea of the architeture and explain how it is designed to provide an alternative to MIM web.
So in a way, I guess there is nothing new as a lot of this has been done for various systems (usually closed), and at the same time it is very new because it is trying to build those pieces for the open web, using open standards, and building on logical frameworks in a completely decentralised manner. (or as far as is reasonably possible to do effectively to start with).
Spencer Breiner said:
I would think that Delete could be implemented as a Write one level up the tree.
Is access downward closed, in the sense that read/write access to a parent node would also allow access to the children?
I started looking at doing delete by looking one level up tree, but that looked very awakward.
So I wrote a new Lens based Solid Server - this time really built on Lenses - since those allow deletes and modification. The trick is to think of a web server as an infinite tree of resources accessible by paths, where most of the paths lead to None.
A few other nice features fall out when one does that: such as being able to create intermediate directories with one PUT, which is how many Solid servers are implemented. That tends to indicate that this is the right model.
(Some examples here).
This model does not deal with access control though, and of course it is not very efficient, as all changes to the server have to be synchronised.
The next thing I need to do is find a way to integrate the Web Server Guard agent into the picture. Reading @Jules Hedges's very helpful 2018 blog post Lenses for Philosophers he points out right at the beginning that Dialectica Categories are types of Lenses, with proofs and disproofs composing. And in a way we can also think of a server and a client as engaged in a game with some simple rules for requests and responses. The Guard and the client can use the whole web as a database to proove facts though, with proofs of the form Web ⊢ Request X allowed
Is there a reson why GET (= view part of a lens) and POST (= update part of a lens) don't exhaust all the needs of a server-client relationship? What's the matter with PUT & friends?
yes HTTP GET is a view: it returns a representation of the state. (REST: Representation of State Transfer). There are optimisations such as SEARCH that are not yet much used.
POST creates a new resource when content is sent on a container. I model that as an adding a new element to a container's Map of type Map[String,Resource].
POST is also used to append to resources that have a monoidal structure (eg RDF Graphs, or log files), and in a way one can think of a container has having a monoidal structure: a map of path elements to content, where POSTing adds a new pair.
DELETE removes an element from that map.
But if you want to change an existing representation, which is what the update method of a view is mostly about, then you need PUT (PATCH is an optimisation of PUT).
PUT is perhaps the closest to the update method PUT: A -> S -> S . You can create a new resource with PUT. I don't think you can delete a resource with PUT though.
(see the wikipedia page on HTTP Methods).
So the question would be why would not GET and PUT alone work?
I think that could have worked. But POST is important as it allows the server to create a new name for a resource without the client needing to know if that was taken in advance of sending the message. There is something of the naming speech act in POST, like when one baptises a child or a ship.
Henry Story said:
So in a way, I guess there is nothing new as a lot of this has been done for various systems (usually closed), and at the same time it is very new because it is trying to build those pieces for the open web, using open standards, and building on logical frameworks in a completely decentralised manner. (or as far as is reasonably possible to do effectively to start with).
oh the problem of specifying AC policies in RDF is very interesting. there is the technically completely disjoint, but conceptually related question who would be generating the specifications. very nice.
dusko said:
there is the technically completely disjoint, but conceptually related question who would be generating the specifications. very nice.
If I understand your question correctly, the process would be as follows. Let us start for illustration from an individual and his Freedom Box (for those who may not know here is a talk from 10 years ago by Eben Moglen , the author of the GNU Public licence (the legal powerhouse behind Linux, the free operating system that runs Android an all of Google's servers).)
As you start up your FBox you login with a password perhaps, and that launches a client that will act as your personal wallet, keeping your personal keys, verifiable credentials, etc... by saving them to your FBox (not to be confused with FaceBook). Note you could place your FB behind a Tor network. I have called that type of app a Launcher App. It can read and write the access control rules - since the web is now read/write - to your FB Pod (Personal Online DataStore) and it signs http headers for other apps to allow them access. Initially you alone have all rights, and slowly you can open up different parts of the information space on the box: the Launcher App (a.k.a Wallet in the Self Sovereign Identity world (many good ideas there, but sometimes over complex implementations)). So it is a process of you giving more access to different people by writing the access control rules via a trusted app to your Pod. Such writing should be as easy as dragging and dropping icons into circles , or whatever the best UI designers can come up with.

There is a more recent talk by Eben Moglen FreedomBox Turns Ten, where he gives a history of the internet, and of the impact of the Free software movement on the world. If you thought computing was just a technical thing, here you can see it's geopolitical and spiritual dimensions.
A key part of the argument on the Freedom Box is an explanation of the Man in the Middle Business model that @dusko explained so well mathematically
Around minute 40, Eben Moglen brings in eccology.
Henry Story said:
So the question would be why would not GET and PUT alone work?
Correct!
Henry Story said:
yes HTTP GET is a view: it returns a representation of the state. (REST: Representation of State Transfer). There are optimisations such as SEARCH that are not yet much used.
POST creates a new resource when content is sent on a container. I model that as an adding a new element to a container's Map of type Map[String,Resource].
POST is also used to append to resources that have a monoidal structure (eg RDF Graphs, or log files), and in a way one can think of a container has having a monoidal structure: a map of path elements to content, where POSTing adds a new pair.
DELETE removes an element from that map.
But if you want to change an existing representation, which is what the update method of a view is mostly about, then you need PUT (PATCH is an optimisation of PUT).
PUT is perhaps the closest to the update method PUT: A -> S -> S . You can create a new resource with PUT. I don't think you can delete a resource with PUT though.
(see the wikipedia page on HTTP Methods).
It seems like DELETE and POST are both versions of PUT with (co)side-effects, namely the creation/elimination of a resource.
If PUT has type A→S→S, then DELETE has type A→S→1 (this can be non-trivial is there are other side-effects, such as errors and IO and so on) while POST has type A→S. So you see how A→(S+1)→(S+1) can encompass both (dep types would allow us to be more precise)
@Matteo Capucci (he/him), yes, we have S+1 appear . It is the Option[X] functor in Scala and has two subtypes and None and Some[X], meaning it is the co-product 1+X .
I modelled a Container as a recursive type C=Z×(1+C)P×(1+R)P where Z is creation time, but could really contain all kinds of metadata, P is a path segment eg foo in /foo/ and R is a resource, perhaps a string of bytes and a mime type (to interpret those bytes). The functions from P to the optionals reflects a scala Map which is a partial function.
I split the map of containers (1+C)P from the map of resources (1+R)P because we make a distinction between /foo/ the name for a container and /foo/index.md the name of a resource.
I see this C as a tree, with multiple leaves and multiple branches, each named, at every junction. It should remind one of a file system.
So paths refer to resources as follows.
/ to the root container eg. https://w3.org/ /foo/bar/ to the bar container of the foo container of the root or 1 if something did not exist /foo/bar/baz.html to the baz.html resource of the bar container of the foo container or 1 if something along the way went missing .
So a Lens uses a path to focus into one of (1+C)P or (1+R)P at various depths. Then one can create, delete or edit a resource by changing one of those functions.
(Now you can all get summer jobs building web servers :-)
Matteo Capucci (he/him) said:
It seems like DELETE and POST are both versions of PUT with (co)side-effects, namely the creation/elimination of a resource.
In the model I gave here which I think represents this as a lens into a tree, they all change a map in a container. But POST increases the size of the map and DELETE decreases its size. At the same time one does get a feeling that those are side-effectful, especially POST... (perhaps just because the server can creates the name?)
If PUT has type A→S→S, then DELETE has type A→S→1 (this can be non-trivial is there are other side-effects, such as errors and IO and so on) while POST has type A→S. So you see how A→(S+1)→(S+1) can encompass both (dep types would allow us to be more precise)
I think DELETE has type 1→C→C rather than A→S→1, as the Lens always has to return a new global state (root container in our use case). What is happening is that DELETE requires no input. (I use C as the state here).
I have a getterpart of a lens as C→(1+C)+(1+R) depending on the path (does it end in / or not?).
I thought the setter part of a lens was of the form (1+R)P→C→C or (1+C)P→C→C depending on the path. Then PUT, POST, DELETE are restrictions on that setter, with POST increasing the map size. and PUT changing the value for a given path. But I wonder if that is good modelling...
Ah. The problem is that if the type of GET is C→(1+R) then the range of that function should be what we are using in the lens setter too. I have been thinking that I have a function (1+R)P→C→C but we should have
(1+R)→C→C.
And that works for PUT and DELETE. Indeed!!!
PUT is R→C→C and
DELETE is 1→C→C
So POST is the man out. POST requires the container to be monoidal -or something like that. It requires one to be able to add 1 element to the function (1+R)P and for containers to add an empty container to (1+C)P.
PUT is also sideeffectful in that I have modelled it so that if one PUTs something on container with intermediatePATHs that don't exist then it will create those intermediate containers. I was surprised to see that the lens laws don't speak against that.
I would have to model this in Agda to check if I have not hacked something illegal somewhere else.
I see this thread has moved directions. I am interested in all things category theory + model based security so let me know if any of you want to meet and discuss
It just made a little detour. Those last part on modelling web servers may have been better in any number of other threads, but it should be useful if one wants to model access control on the web.
Mind you what part of model based security interests you? :-)
Any form of security modeling that specifies and challenges a system. My predominant interest is of course cyber physical systems but I think one can do a lot in just software systems as well since the model based security world is pretty behind on the math than other security fields.
Ah good. I am coming at this from an engineering perspective: how do you allow a decentralised access control system that can be used by billions easily to work on top of the Web more or less as it exists. So I am looking for mathematics that can help specify that. We have good demonstrations working, and experience building parts of it based on 20 years of standardisation effort. But having more mathematics would help a lot.
As there are so many different areas that come together I came to CT to help see the big picture.
So I guess you come in once we have specified the system :-) (Well we have some initial specifications already)
@Henry Story nice that AC has moved beyond computer resources and onto the web. but is the AC for the nowadays web really what eben moglen talked about? ((BTW thanks for explaining about linux :))) but i wonder whether the fact so much of google is built on GPL makes the GPL into a powerhouse or a suckerhouse...))
web 2.0 looked like a gigantic semistructured database. the resources on it and the credentials used to control access to those resources where data. which means they can be copied: if i steal your credentials, then both you and i have your credentials and for all purposes on the web of data we are indistinguishable.
in the menatime, the web is not just on the internet. most authentications use objects that cannot be copied, and out of band channels, phones. and phones authenticate each other through their humans, over lunch. back in 2000s, i could give you the credentials to enter my office by shaking our phones together. a fuzzyt extractor would get extreact a key for a BLAKE-secured channel and pass a 4096 key into your phone, which could only be used once, and which was bound to the device that it is on. but then Visa realized that the NFC would spell the end of credit cards, and became very active within the IETF. and we still use credit cards. but they are a part of access control on the web...
i guess to capture credentials that are not date you will need to move the story about lenses and moore machines from cartesian to monoidal categories, but prolly not much further than that. gets and puts will become quite different from reads and writes --- but not categorically different :)
would that be a fun thing to do?
but even without that -- very nice work! :clap: :call_me:
Hi @dusko , let me reply in little chunks.
You wrote:
Henry Story nice that AC has moved beyond computer resources and onto the web. but is the AC for the nowadays web really what eben moglen talked about? ((BTW thanks for explaining about linux :))) but i wonder whether the fact so much of google is built on GPL makes the GPL into a powerhouse or a suckerhouse...))
In the speeches starting 2010, Eben Moglen engaged a turning point in the free software movement. He argued that it is urgent to consider the hardware on which the free software is running, the location of the data in addition to the more traditional preoccupation of software freedom.
The argument can be put thus: How do you know that your brain is not being manipulated by Aliens to make you think what they want? Especially when all the data is on their servers? See my Epistemology in the Cloud.
Sovereignty is the key advantage of Free Software: That is why companies like Google built all on Free Software from the very beginning. That allowed them to develop their services without being beholden to another large company. Indeed, these awesome US companies have a conception of sovereignty that goes to the core of their strategy. Sometimes one wonders if Nations-States are even aware of the importance of this dimension.
So Eben Moglen's point is that we also need Free Software to run on our machines for our data to be located there. But if we all are going to place our data on our own servers, how do we avoid going back to the 1980s PCs, each of us unconnected atoms, living in an isolated POD, as shown in The Matrix (v4 trailer).
This is why one cannot succeed with just free software and a freedom box. One also needs Linked Data. But then, without Web Access Control and Web Identity, the only choice available to us is
- either to make data publicly readable
- or make it accessible to only a hardcoded set of users
This is very inflexible.
@dusko continued:
web 2.0 looked like a gigantic semistructured database. the resources on it and the credentials used to control access to those resources where data. which means they can be copied: if i steal your credentials, then both you and i have your credentials and for all purposes on the web of data we are indistinguishable.
The big honest change in Web2.0 was the blogosphere, which made headlines every week in the top newspapers for years on end. It changed the web from a read-only medium to the beginning of a read/write medium, allowing people to quickly start producing content.
The blogosphere did not have a suitable authentication mechanism, though. OpenID started off being discussed together with the RDF friend of a friend (foaf) vocabulary. If that had been pursued, they would have had the social networking piece needed to grow. But there was a war between syntax and semantics going on: very large players like IBM made a huge noise for XML and SOAP, which was the future in 2004 the way Blockchain was the future 4 years ago.
With Access Control the blogosphere could have staved off spam, and turned into the web we want.
Instead it was a lot easier to build a centralised social network like Facebook. Dictatorships are easier to build. But really Facebook is nothing more than a blogging platform with access control.
@dusko wrote
... the resources on it and the credentials used to control access to those resources where data. which means they can be copied: if i steal your credentials, then both you and i have your credentials and for all purposes on the web of data we are indistinguishable.
That story on the relation between data and resources is overly simplified. URLs refer to resources that return representations - data. But the resources named by URIs are unique and individual: they are named coalgebraic streams of representations perhaps. I can copy the representation of one resource to server that is true. I can copy the front page of https://facebook.com/ to https://facebook.com.trust.me/ and that is a well known phishing technique. But even though humans can be confused by this similarity, the URLs are clearly different and a computer can easily notice that. Furthermore the links on the web do not point to the new fake trust.me URL. The Links to facebook pages continue to point to the original web site https://facebook.com/ .
Mathematically say I have a function get:W→(W×R)U which given a state of the web W returns a function from URLs U to states of the Web and Representations R. (The web is always changing). If I take some u:U at some point of the web I can get(w)(u)=(w′,r) and then put that representation r somewhere else, say on v:U. We will have u=get(w′)(v) for any future state of the web w' where the resource is not changed. But the links pointing to u will not be pointing to v. So really we have two pieces of data (r,u),(r,v):R×U. Those we call named Graphs in the semantic web. I think this moves the web into the space of multigraphs or simplicial sets.
That is what allows us to place public keys at URLs on the web, and use those URLs to identify an agent. That was what we proposed doing with WebID 12 years ago or so, and I am now working on a more flexible version called HTTP-Sig.
Basic HTTP Sig Sequence Diagram
@dusko continued:
i guess to capture credentials that are not date you will need to move the story about lenses and moore machines from cartesian to monoidal categories, but prolly not much further than that. gets and puts will become quite different from reads and writes --- but not categorically different :)
yes, I think I have read a few times about Monoidal categories, and I should be able to read your paper now, Tracing the man in the middle in monoidal categories. So that will go right up there to the top of my list.
Interestingly enough RDF can be expressed in terms of monoidal categories already as @Evan Patterson showed in Knowledge Representation in Bicategories of Relations if I remember correctly.
I wonder if anyone has done lenses and monoidal categories?
would that be a fun thing to do?
Definitely. If anyone else with some mathematical background wants to join thinking about this, that would be very helpful.
We absolutely need mathematics to clarify the structures that have been discovered bottom up by the web community, if we want to make secure and rapid progress.
@Henry Story wrote
I wonder if anyone has done lenses and monoidal categories?
If I can start with something really simple like this, and perhaps write a proof out in Agda (cause I know it and it is stricter than Scala), then I could use that to help the group come to some decision on the modes of access.
Henry Story said:
@dusko wrote
... the resources on it and the credentials used to control access to those resources where data. which means they can be copied: if i steal your credentials, then both you and i have your credentials and for all purposes on the web of data we are indistinguishable.
That story on the relation between data and resources is overly simplified. URLs refer to resources that return representations - data. But the resources named by URIs are unique and individual: they are named coalgebraic streams of representations perhaps. I can copy the representation of one resource to server that is true. I can copy the front page of https://facebook.com/ to https://facebook.com.trust.me/ and that is a well known phishing technique. But even though humans can be confused by this similarity, the URLs are clearly different and a computer can easily notice that. Furthermore the links on the web do not point to the new fake trust.me URL. The Links to facebook pages continue to point to the original web site https://facebook.com/ .
Mathematically say I have a function get:W→(W×R)U which given a state of the web W returns a function from URLs U to states of the Web and Representations R. (The web is always changing). If I take some u:U at some point of the web I can get(w)(u)=(w′,r) and then put that representation r somewhere else, say on v:U. We will have u=get(w′)(v) for any future state of the web w' where the resource is not changed. But the links pointing to u will not be pointing to v. So really we have two pieces of data (r,u),(r,v):R×U. Those we call named Graphs in the semantic web. I think this moves the web into the space of multigraphs or simplicial sets.
That is what allows us to place public keys at URLs on the web, and use those URLs to identify an agent. That was what we proposed doing with WebID 12 years ago or so, and I am now working on a more flexible version called HTTP-Sig.
Basic HTTP Sig Sequence Diagram
you have obviously thought about this a lot, probably a lot more than i, but nevertheless, what you describe is not the story about data and resources themselves, as entities in the world, but of data as resources as we at some point decided to represent them, and then maybe confused our representations and reality.
in reality, the difference between data and resources is simpler than in standards. the number 3 is a data item. a trunk of a tree is a resource, eg for building a cabin. what is the difference between them? if i want to count 3 times to 3, i make 2 copies of 3, and use one to count the other one. we tend to go pretty far with that, since copying data is so easy (in principle costless). but if one tree is not enough for the cabin, i need to wait for another tree to grow. trees are not copiable. that is what makes them into a resource: they are easy is easy to use, but hard to get by.
the distinction is the foundation of security. how secure is a lock depends on the availability of the copies of the key.
finding data operations that are easy in one direction but hard in the other direction is hard. and based on obscurity of, say, an NP complete P algorithm. so people are increasingly using things that are harder to copy...
copying is done in cartesian categories by the diagonals. the only energy-expending operation, erasure, is the projection. there are no diagonals or projections in monoidal categories. in a string diagram, strings conduct resources. some of them come with copying nodes and the deletion nodes. modeling how the copiable data and the uncopiable objects interact is similar to modeling hos classical data interact with quantum data, since these two are also defined by copiability and non-copiability and non-deletability...
some math models clean the conceptual slate and first of all simplify things :)
Henry Story said:
dusko continued:
web 2.0 looked like a gigantic semistructured database. the resources on it and the credentials used to control access to those resources where data. which means they can be copied: if i steal your credentials, then both you and i have your credentials and for all purposes on the web of data we are indistinguishable.
With Access Control the blogosphere could have staved off spam, and turned into the web we want.
there is a historic precedent for this. spam is an abuse of a costless public utility. an instance of the commons. the response to earlier instances of similar abuses of the commons was always the same: first access control, then appropriation. the Enclosure. you mention that FB already performed some of that.
not distinguishing technical tasks (securing an aset) from political tasks (right to privacy, lack of right for privatizing public utilities) has been very costly. private companies use public utilities to gather private data; nations use public utilities to manipulate each other's governments; terrorist organizations use public utilities to draft terrorists. those are not engineering failures. those are categorical failures: people got hypnotized by their computers and started thinking that national security is an advanced form of software engineering. organizign the world like an operating system. but they forgot to tell putin.
Lol, the reference to spam made me smile. One of the proposed antispam solutions was proof-of-work, waaaay before we saw it assume its central role in blockchain consensus. The idea is simple: I have to prove that I did some computational work to send a email. In this way, spam becomes prohibitively expensive. This is exactly related to what Dusko was saying: It's about turning data (as in costless operation) into resources (a costly operation).
@dusko wrote:
Copying is done in cartesian categories by the diagonals. the only energy-expending operation, erasure, is the projection. there are no diagonals or projections in monoidal categories. in a string diagram, strings conduct resources. some of them come with copying nodes and the deletion nodes. modeling how the copiable data and the uncopiable objects interact is similar to modeling how classical data interact with quantum data, since these two are also defined by copiability and non-copiability and non-deletability...
I wonder where this copying vs not-copying distinction turns up in @Evan Patterson 's Knowledge Representation in Bicateogries of Relations, as he uses String diagrams from monoidal categories to explain the semantic web tech I am talking about...
Indeed what I am looking for is the distinction between copy-ability and non-copyability. Perhaps there is something more to it though.
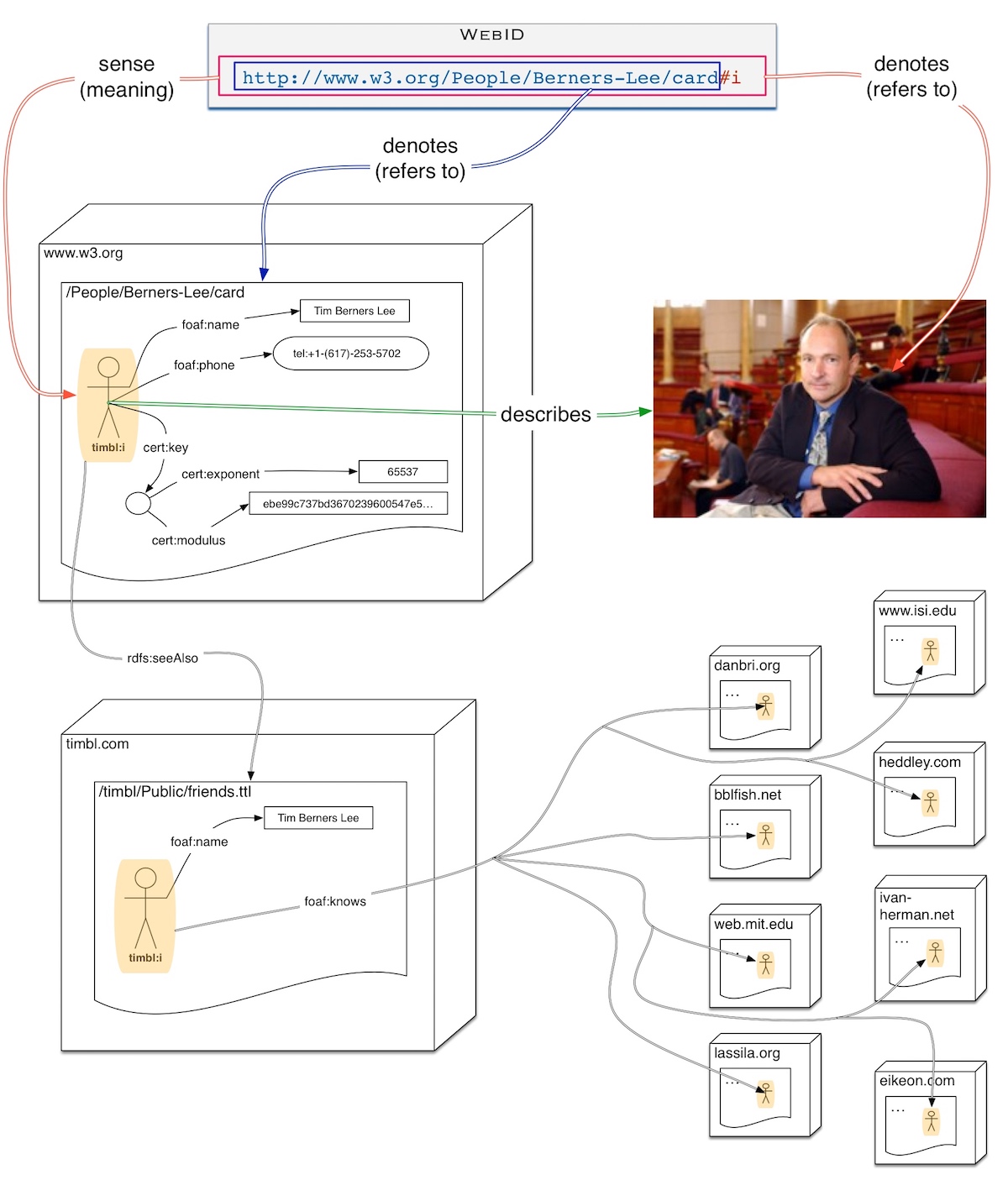
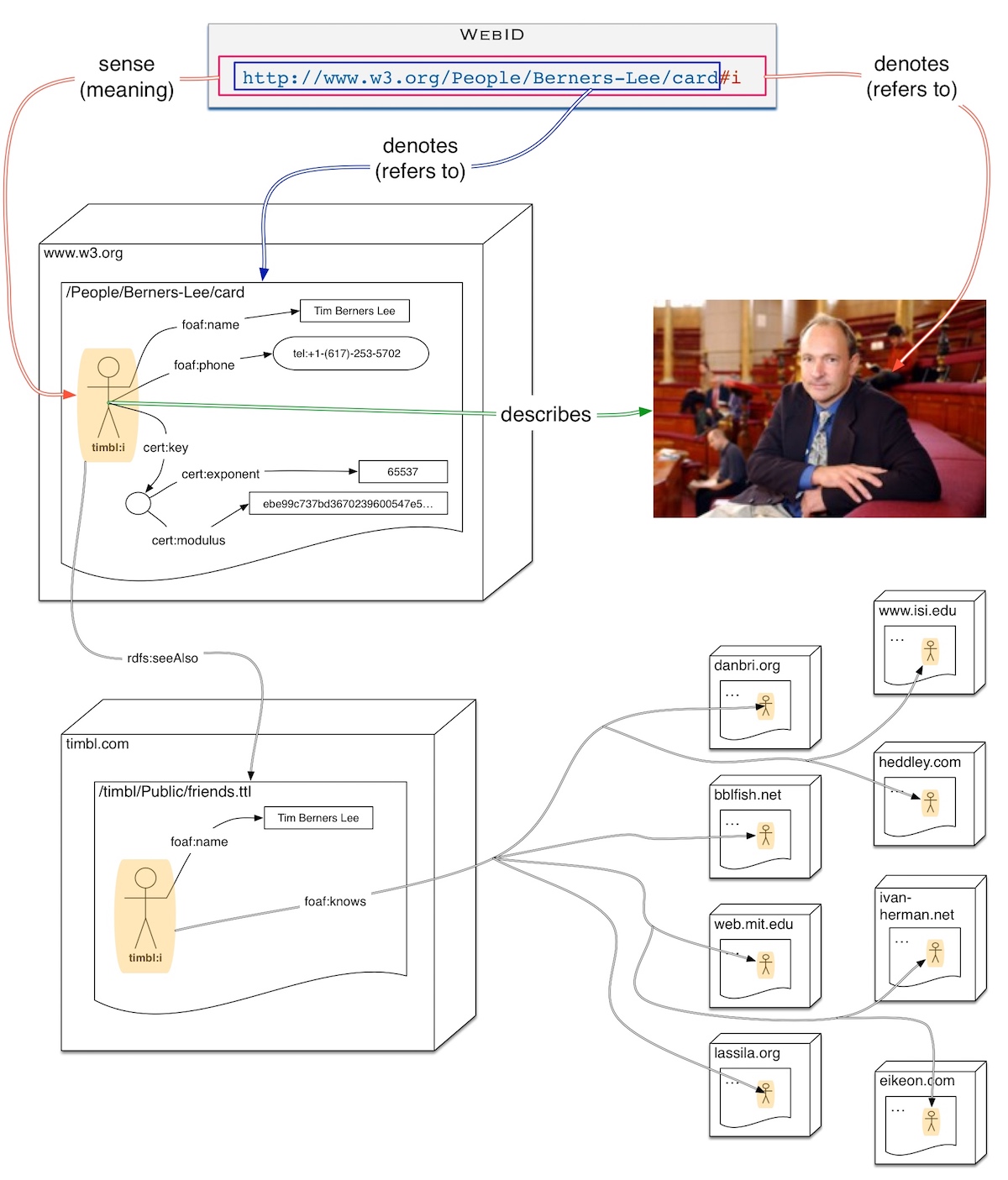
An RDF graph can be copied from a URL1 to a URL2, and we can ask if two graphs are isomorphic, and yet they are different resources. I showed this this slide from a 2014 talk I gave at Scala eXchange. We can see three computers - represented as boxes - named www.w3.org, www.copy.org and www.piratew3.org.
Slide with 3 Web Servers and 2 copies of a document
All three machines have a copy of the graph located at https://www.w3.org/People/Berners-Lee/card consisting of 2 relations
@prefix foaf: <http://xmlns.com/foaf/0.1/> .
<#i> foaf:name "Tim Berners-Lee";
foaf:made <> .
This RDF Graph in Turtle syntax, says that the entity referred to by <https://www.w3.org/People/Berners-Lee/card#i> has name "Tim Berners-Lee" and is the agent that made the document <https://www.w3.org/People/Berners-Lee/card>.
Note that there are two different meanings of copy here:
- The copy of the graph at
www.copy.org was produced by fetching the w3c.org graph, and transforming all relative URLs into absolute ones by prepending the document's URL. As a result the document the foaf:made link still points to the original document as shown by the arrow. That is the graph is isomorphic to the copy.
- The piratew3 copy on the other hand did not absolutize the URLs but just copied the data. As a result it created the new URLs
<https://www.piratew3.org/People/Berners-Lee/card/#i>. That graph is not isomorphic with the original at the graph layer at least. It may be syntactically isomorphic. Still clearly the RDF notion of isomorphism caputres the sameness of meaning idea.
What we notice though is that all the external URLs shown by links coming from outside the slide on the top left named "foaf:knows" point to the w3.org document, not to the copies.
So we clearly have something important happening in the naming here, and I am really keen to find the maths for that. I may be a bit sensitive to naming because in the late 1980s while studying a Masters in Philosophy at Birkbeck college London, I read a 500 page book The Varieties of Reference - I am sure that @David Corfield will have heard about. I read it with interest but could not imagine at the time how this could ever be useful. So I was really surprised when I discovered how fundamental naming is to the web.
Naming may also be related to monoidal categories though. Earlier this year I came across monoidal categories in Brendan Fong's thesis on monoidal categories and open systems after listening to a very nice introductory talk by John Carlos Baez on the topic. If I understand correctly the Inputs and outputs of the widgets which allow them to be composed act as names.
At least that is how F. Patel-Schneider in Integrity Constraints for Linked Data seems to use them. I was reading that paper late last year while documenting the Agda proof . I think the argument there is that the URLs of the Semantic Web is what allows it to be an open composable system of graphs. And that also seems to fit.
Fabrizio Genovese said:
Lol, the reference to spam made me smile. One of the proposed antispam solutions was proof-of-work, waaaay before we saw it assume its central role in blockchain consensus. The idea is simple: I have to prove that I did some computational work to send a email. In this way, spam becomes prohibitively expensive. This is exactly related to what Dusko was saying: It's about turning data (as in costless operation) into resources (a costly operation).
I agree that the cost element has an important role to play in security. DNSsec and other technologies make it very difficult to break into the DNS by using cryptography. But the Internet started with the basic unprotected Domain Name System for naming machines. So I think here the uncopyability may be also related to the physical nature of the computation and the named machines.
There is also another way I have been thinking of this uncopyability: and that is that a GET or PUT request are something akin to speech acts. See my Slide in 38 of a talk I gave on the Philosophy of the Social Web in 2010. As events those cannot be copied, as they are unique. So I wonder if Monoidal Categories have also turned up in Speech Act analysis?
I guess @Valeria de Paiva might know if there is work in Linear Logic and Speech acts.
We were discussing above how one could model a web server with Lenses.
But now I wonder how much co-inductive types change that.
In 2017 @Conor McBride had a series of lectures on Agda which I watched last year where he shows how codata pops up just in the client/server communication. I have a feeling that a good model of the web needs to use that. So I wonder if this duality of data and codata would affect the idea of modelling a web server with lenses.
I could take a month to try to model this before the end of the year, if someone could guide me. The aim would be to have some good model of the web to be able to provide serious answers to some questions that have been coming up in Solid.
hi @Henry Story I'm sorry, I don't know how I missed this message from Sept?! well I know about Linear Logic applied to dialogs (work of Christoph Fouquere and Myriam Quatrini) and dialogs usually include "speech acts" (https://hal.archives-ouvertes.fr/hal-01286851/document). But I don't know about something specifically on "Linear Logic and Speech acts".
As a matter of interest here is how @Brendan Fong 's thesis on open systems comes in useful in a discussion on access control in Solid. I now have a handy answer to the question "what is an open system?". :-)
(Of course using this means I will have to read that thesis or an update in more detail at some point)
Thanks @Valeria de Paiva for the links to the paper 2016 Ludics and Natural Language: First Approaches. I think I also came across this 2011 Speech Acts in Ludics by MR Fleury, S Tronçon. I had come across Ludics and the Web: Another reading of Standard Operations a few years ago. But I think I thought something was a bit odd when I read it. It may have been my grasp of Ludics that was nearly 0 at the time, and still is very minimal.
Thanks for the other references @Henry Story , useful to know about them!
It would be nice if this channel were also public :-)
(I just remembered that I should be working on the following not so much on entropy!)
Btw, I think I have found a good practical case for using Category Theory in Security and Access Control that follows on the discussion we had over 6 months ago. Well at least it looks like it's very close.
Remember a Solid web server adds a link to every resource that contains a description of who can access. (see above). At present those are just lists, but with OWL one could create sets by descriptions. For example the set of all friends of a friend of someone. (more about foaf in the bicategories of relations article). So if we extend bicategories to have linked data like we have linked web pages, where one can follow links from my profile to anyone of my friend's profiles, who all host theirs on their Freedom Boxes (see above), then we have a decentralised system.
linked profiles starting from a WebID
But we have a problem. Say I conservatively only have 100 friends, and my friends have 100 friends with no overlaps. Then when I authenticate to a resource that requires me to prove that I am a friend of a friend of someone I could prove ownership of my WebID, but that would require the server in the worst case to search all the profiles, since some may have been updated in the meantime. That could require 100 connections on the server's part to find all the friend's profiles. If we then move one level further to friends of friends of friends, then the server would end up having to search 10 thousand profiles. That would not make for a very efficient or reactive system.
The answer to this is quite simple: if the client authenticates, then it knows the relations that is correct, so it should be able pass the proof along with the request. Or perhaps a proof is not needed but just enough of a hint of a proof hint. That could reduce the search space from 10 thousand to 1 or 2 requests.
I started looking into this recently, and it looks like all the client has to do is pass a path starting from the rules in the acl. That sounds very much like some things I heard about categories being proofs, which would be handy as that could help serve as a proof that such a procedure constitutes a proof.
It looks like I am going to be able to work on implementing this. It would help if I could find a tutor (on the CT side) to help guide me in the process if anyone here is interested.
Following up on the above idea of using proofs on the web, there is also work described in the presentation of n3 on slide 14:
[] a r:Proof, r:Conjunction;
r:component <#lemma1>;
r:component <#lemma2>;
r:gives {
:Socrates a :Human.
:Socrates a :Mortal.
}.
And on slide 23 the adavantages of using proofs to reduce the search space on the server are explained. Work on this goes back to 2006 at least, see the no longer working web slides towards proof exchange on the semantic web.
I made a recording of a demo to the W3C Solid Community Group illustrating the type of access control protocol I was talking earlier in this thread https://twitter.com/bblfish/status/1666547828506742788
I am reading the 1992 Authentication in distributed systems: theory and practice by Butler Lampson, Martín Abadi, Michael Burrows (who wrote the AltaVista search engine), and Edward Wobber. (I had read other articles around it, but missed this very detailed one). It describes the modal "says" operator (S says P). They were working at Digital Equipment's Systems Research Center named SRC - which helps understand some of the examples.
Abadi later described an index Monad based version of this in the 2006 Access control in a core calculus of dependency. (the index is on the type of Agents).
Are there any advances in this area that should be looked to?
I think it depends in which direction you want advances. Deepak Garg wrote a phd thesis at CMU on Authorization logic, a long time ago, 2009 https://people.mpi-sws.org/~dg/papers/papers.html#theses. but Abadi's work on DCC has had quite a following.
Valeria de Paiva said:
I think it depends in which direction you want advances. Deepak Garg wrote a phd thesis at CMU on Authorization logic, a long time ago, 2009 https://people.mpi-sws.org/~dg/papers/papers.html#theses. but Abadi's work on DCC has had quite a following.
Thanks for the pointer. It looks like Garg's PhD thesis puts forward a logic of saying-that that have a number of advantages, including a details sequent calculus of saying that, and a few improvements to the rules put forward earlier by Burrows, Abadi, etc...
What I find the most interesting is that hypothetical reasoning is always performed relative to the claims of a principal k, which is indicated in the hypothetical judgment by writing the latter as Σ;Γ⊢ks .
Σ⊢k≽k0
−−−−−
Σ;Γ,k claims s⊢k0s
where ≽ gives a partial order of principals. Σ is the context of typed variables and Γ the context of Judgements such as s true or k claims s where the latter is just a shorthand for the otherwise confusing if without partenthesis (k says s) true
What this shows is how we use rdf datasets, which consists of a default graph, and a set of named graphs. The default graphs is the one that has a hidden implicit agent pronouncing it, so it matches very nicely.
Deepak Garg applied it to a Unix file system because he wanted to have it put to use quickly and without needing to change existing software.
But that I think leads to it being prone to a Confused Deputy attack which was very well explained in the 2009 article "ACL's don't" by Tyler Close who argued for capability systems instead. The problem is you cannot just change the OS rights, you have to change the programs themselves to take capabilities.
But my feeling is that capabilities are just proof objects of the "says" logic, which should be of interest to @Valeria de Paiva :-)
Without the says modality capabilities are pretty much incomprehensible.
But with them understood as proof objects I think it makes a lot more sense, and we can see that what is needed is an incorporation of that into Access Control Logics. The web is essentially multi-agent, and so the "A says p" indexed modality has to be at the core of web access control logic.
https://github.com/co-operating-systems/PhD/blob/main/Logic/ACLsDont.md
Now Tim Berners-Lee, Dan Connolly and others in 2009 also worked on the says modality using N3, an extension of RDF with rules. I have pointers to that work here:
https://github.com/co-operating-systems/PhD/blob/main/Logic/ABLP.md
Now Deepak's Phd thesis was written up in terms of sequent calculus. I wonder what the best way to translate that to the semantic web would be?
I remembered that @Evan Patterson 2017 Knowledge Representation in Bicategories of Relations comes with an appendix of a sequent calculus for RDF. So part of the work has been done...
Hi Henry, I don't know about
But that I think leads to it being prone to a Confused Deputy attack which was very well explained in the 2009 article "ACL's don't" by Tyler Close who argued for capability systems instead.
and in my books a logic is good/decent/sensible if you can give it sequent calculus/axioms and especially Natural Deduction (ND) presentations, proved equivalent (after all they are presentations, the essence should be the same). so you're right ! I'm very interested in a logic of multi-agents/multi principals for "P says that" with different presentations, proved equivalent. actually I have been interested in that since 1995 (see the project I wrote, but couldn't develop as I moved to Birmingham). I will investigate the references you mention, many thanks! (and of course sequent-calculus should be cut-free and ND should satisfy normalization, :wink: )
It makes sense that if Guard receiving proofs is to prove access to a resource it should only go on evidence provided, which moves one as I understand to constructive logic. So RDF should be useable that way... I will try to go with Deepak Garg's work, and consulting your earlier work you mentioned.
In the past week I was busy trying to write up access control use cases using Verifiable Credentials, but I think I hit a snag in their semantic mapping, of the json-ld contexts. It seems that they intended to use the right model that can nicely be interpreted with the "says" modality, but that that part was not tested. They were aiming I think at developers that would play with the Json encoding without ever thinking of the logical structure behind it.
But without a good logical encoding extensibility becomes very difficult and noisy.
https://github.com/w3c/vc-data-model/issues/1248
I think I worked out what the main logical problem with W3C Verifiable Credentials is in this longer comment.
Essentially they are modelling a verifiable credential wrongly. This does not matter so long as people are only using the VCs syntactically in JSON, but becomes noticeable as soon as the mapping to RDF is made (ie to the positive part of First order logic - regular logic using ∧,⊤,∃ . So this is how they model a Credential
Current model of a VC
Bizarrely the signature is placed in a node, but the graph to be signed is outside, so one cannot tell what is being signed!
(The node colors are arbitrary btw - and are just there as reminders of colors used in Figure 6 of the spec). The only things that matter are where the graphs are located: on the default surface or on a surface in a node of the default graph - eg. the green surface here.)

The graph above is logically equivalent to the following (among many others), where an owl:sameAs relation goes from one arbitrarily chosen node to itself. Many other such graphs could be produced. In any of such graphs it would be impossible to guess what the signatures was a signature of.
image.png
The answer is obvious and easy: place the objects to be signed inside a node (the square ping surface below) so that the signed graph is closed.
image.png. Then all those problems disappear.
You'd think that having shown the problem, adoption of the solution would follow (or at least discussion of other possible ones). But the authors have a view that the charter forced them to produce illogical standards even though they can't find text where it is said!
Sigh!
I can't imagine architects building high rises and pushing mathematics aside as unimportant or just too theoretical. Yet we have this type of people on the web standards groups. My hypothesis is that they came to think that everything is a matter of convention, of majority voting, and then forget that mathematical structures underlie and precede the structures of what they are trying to build and those are not reached by agreement.
Notice how my diagrams above are nicely readable in night and day mode?
I proposed a potential solution for the above conundrum, which feels like it is something that must have been studied mathematically.
A shift operator would take a relation (type) R on a graph G that can have graphs at the nodes recursively, and that would move G into a node and union the objects of the relation R into the new graph with G as a node. I illustrated it here: https://github.com/json-ld/json-ld.org/issues/817
It would be a bit more complex than that, and it to tell the truth, it is not quite a graph transformation problem, but rather an interpretation of a tree (Json) into a labeled graph problem (JsonLD)